redis와 lua스크립트를 이용한 처리율 제한 장치 만들기
처리율 제한 장치(rate limiter)를 개선해보자
사내 서비스의 처리율 제한 장치(rate limiter)의 개선 프로젝트를 하게되었다.
처리율 제한 장치(rate limiter)는 클라이언트 또는 서비스가 보내는 트래픽의 처리율(rate)을 제어하기 위한 장치이다.
이 기술은 서비스나 애플리케이션에 너무 많은 요청이 한꺼번에 몰리는 것을 방지하여, 서버가 안정적으로 운영될 수 있도록 돕습니다.
요구사항은?
요구사항은 다음과 같았다.
Rate limiter용 공통 라이브러리 제작 후 현재 여러 형태로 처리하고 있는 rate limiter을 일관 되게 처리 할 수 있도록 합니다.
기존에는 여기저기 파편적으로 rate limit 로직이 구현되어 있었으며, 로직이 제대로 동작하지 않는 경우도 빈번하게 발생하고 있었다.
어떻게 구현(개선)할 것인가?
- 기존 코드에 영향을 주지 않게 인터페이스 변경은 최소화한다.
- redis 접근을 최소화하여 트랜잭션 오버헤드를 줄인다.
- atomic을 보장하기 위해 lua 스크립트로 작성한다.
- 연산을 최소화한다.
- 요구사항에 알맞는 처리율 제한 알고리즘을 사용한다.
처리율 제한 알고리즘이 뭔데?
- 토큰 버킷(token bucket)
- 누출 버킷(leaky bucket)
- 고정 윈도 카운터(fixed window counter)
- 이동 윈도 로그(sliding window log)
- 이동 윈도 카운터(sliding window counter)
처리율 제한 알고리즘 설명
<details> <summary> 접기 / 펼치기 </summary>토큰 버킷 (Token Bucket) 알고리즘
동작 원리
- 버킷: 이 버킷은 토큰을 저장하는 곳입니다. 시스템에 들어오는 각 요청을 처리하기 위해 토큰을 하나씩 사용합니다.
- 토큰 추가: 정해진 속도로 버킷에 토큰이 추가됩니다. 만약 버킷이 가득 차면, 추가되지 않은 토큰은 사라집니다.
- 요청 처리: 요청이 들어오면, 버킷에서 토큰을 하나 꺼내 요청을 처리합니다. 토큰이 없으면, 요청은 처리될 때까지 기다려야 합니다.
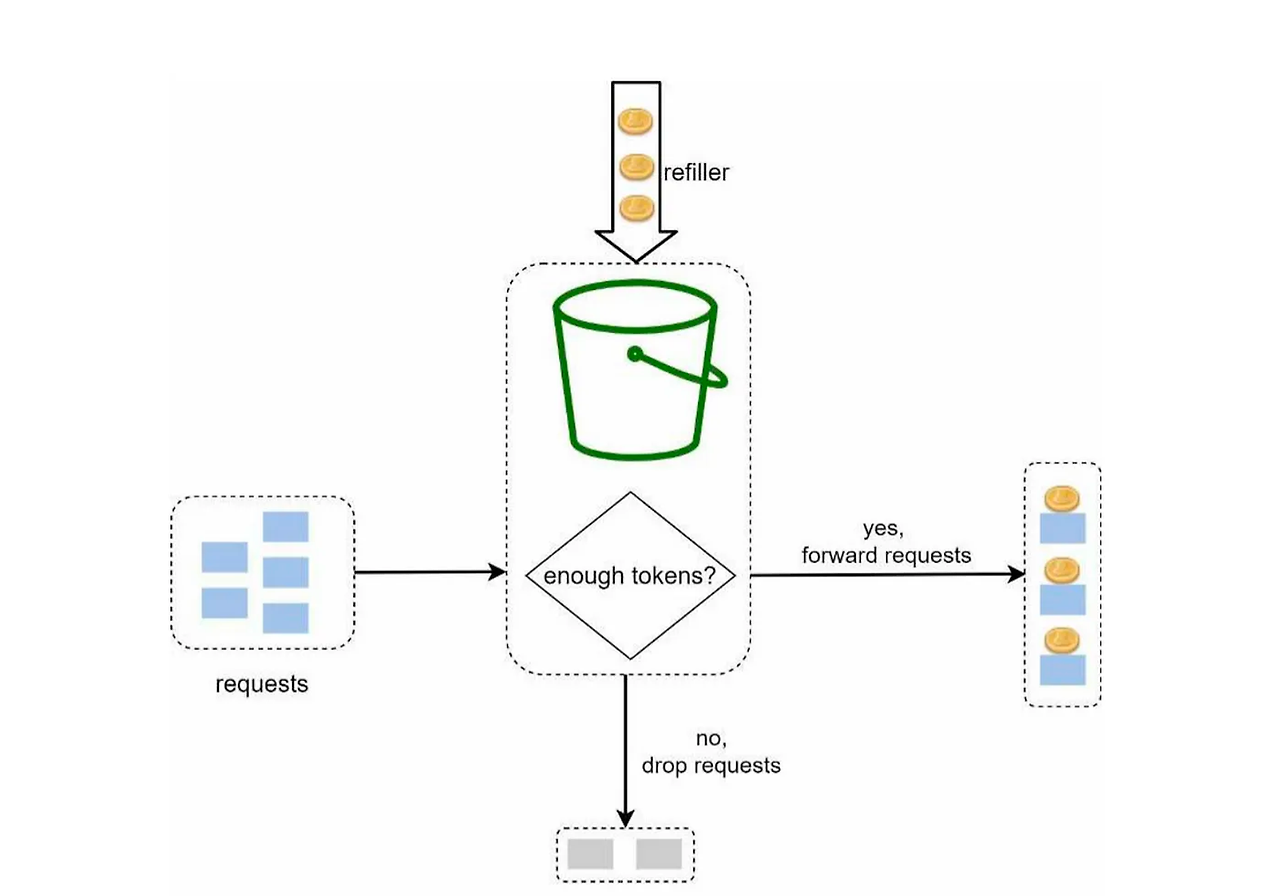
장점
- 구현이 쉽습니다.
- 메모리 사용 측면에서 효율적입니다.
- 유연성: 트래픽이 일시적으로 증가하는 경우, 미리 축적된 토큰을 사용해 이를 처리할 수 있습니다.
- 안정성: 요청이 폭발적으로 증가하는 경우에도 시스템이 정해진 속도로만 처리하기 때문에 시스템이 안정적으로 유지됩니다.
단점
- 복잡성: 구현과 관리가 상대적으로 복잡할 수 있습니다. 특히, 분산 시스템에서는 토큰의 동기화와 관리가 더 어려워질 수 있습니다.
- 토큰 버킷 크기: 버킷의 크기를 적절히 설정하지 않으면, 너무 많은 트래픽을 한꺼번에 처리하려 해서 시스템에 부하를 줄 수 있습니다.
노출 버킷 (Leaky Bucket) 알고리즘
동작 원리
- 버킷: 버킷은 들어오는 요청(물)을 저장하는 역할을 합니다.
- 노출(Leak): 버킷에 구멍이 나 있어서 일정한 속도로 물이 빠져나갑니다. 이 빠져나가는 물은 시스템이 처리할 수 있는 요청을 의미합니다.
- 과부하: 버킷(버퍼)가 가득 차면, 새로운 요청은 버릴 수 있습니다. 이는 네트워크 혼잡 상황에서 시스템이 넘치지 않게 하는 역할을 합니다.
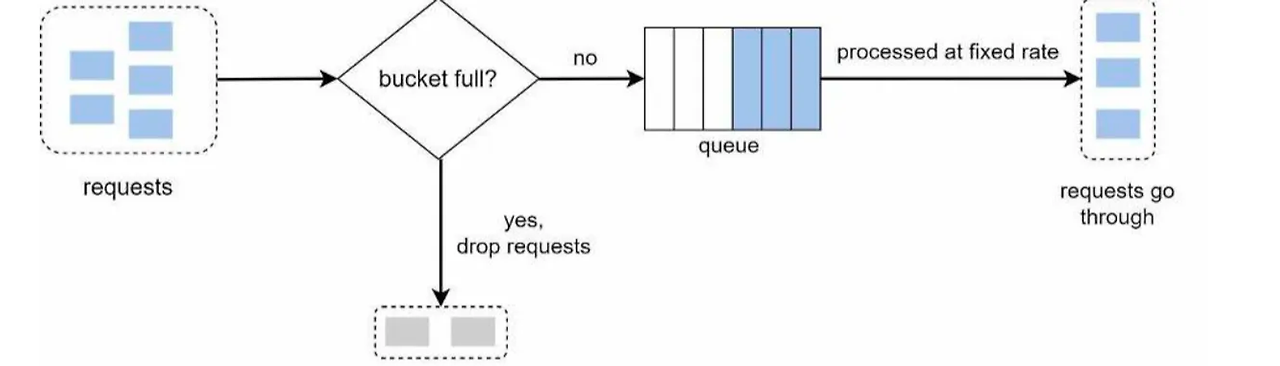
장점
- 큐의 크기가 제한되어 있어 메모리 사용량 측면에서 효율적입니다.
- 균일한 처리율: 시스템이 일정한 속도로 요청을 처리하므로, 트래픽 폭증 시에도 안정적입니다.
- 간단한 구현: 노출 버킷 알고리즘은 구현하기가 비교적 간단하며, 이해하기 쉽습니다.
단점
- 유연성 부족: 일정한 속도로만 요청을 처리할 수 있으므로, 일시적인 트래픽 증가에 유연하게 대응하기 어렵습니다.
- 버퍼 오버플로우: 요청이 많이 들어올 경우 버킷이 가득 차서 새로운 요청을 버려야 할 수 있습니다. 이는 요청 손실을 의미합니다.
고정 윈도 카운터 (Fixed Window Counter) 알고리즘
동작 원리
- 시간 윈도 설정: 고정 윈도 카운터는 전체 시간을 동일한 크기의 '윈도'로 나눕니다. 예를 들어, 하루를 24개의 1시간짜리 윈도로 나눌 수 있습니다.
- 카운터: 각 윈도마다 하나의 카운터가 있습니다. 요청이 들어올 때마다 해당 윈도의 카운터가 1씩 증가합니다.
- 요청 제한: 각 윈도에 설정된 한계에 도달하면, 그 윈도에서는 더 이상 요청을 받지 않습니다. 새 윈도가 시작될 때까지 기다려야 합니다.
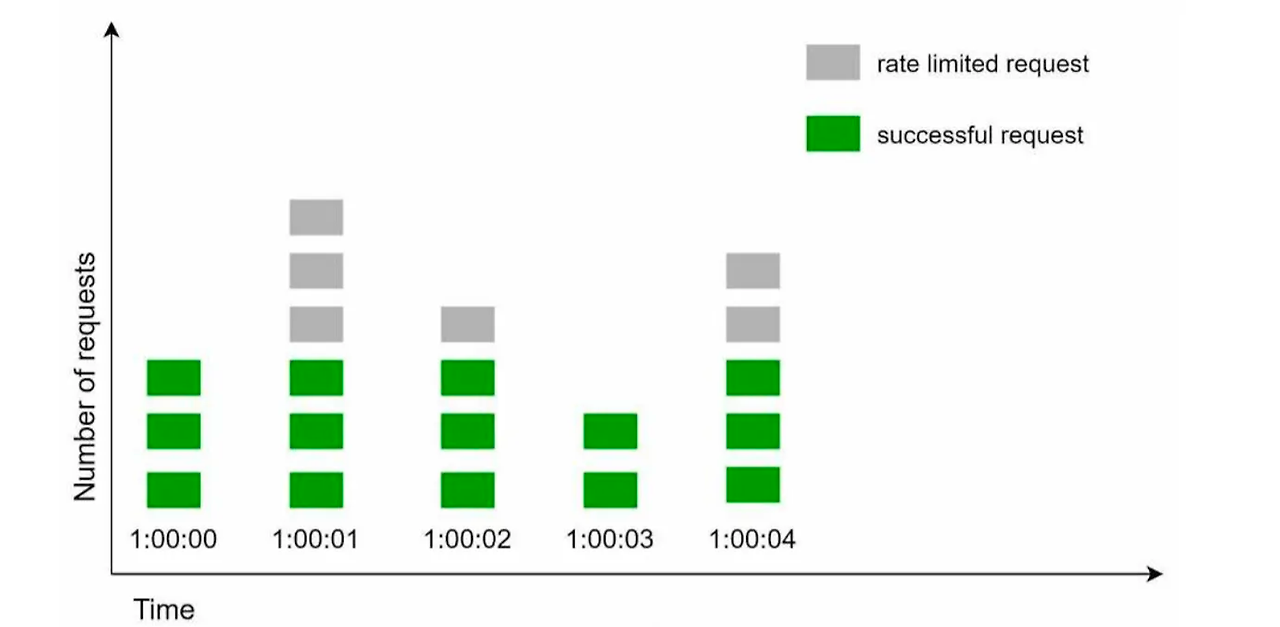
장점
- 단순성: 구현하기 쉽고 이해하기 간단합니다. 복잡한 알고리즘이 필요 없는 작은 시스템이나 애플리케이션에 적합할 수 있습니다.
- 성능: 카운터만 업데이트하면 되기 때문에, 매우 빠르고 효율적입니다.
단점
- 버스트 트래픽 처리 어려움: 윈도가 바뀔 때마다 요청 한도가 초기화되므로, 윈도가 바뀌는 순간에 요청이 몰리면 시스템에 큰 부하가 발생할 수 있습니다.
- 정확한 제한 어려움: 정확한 초 단위로 요청을 제한하기 어렵습니다. 예를 들어, 1분 윈도에서 60개의 요청을 허용하는 경우, 첫 10초에 모든 요청이 몰릴 수도 있습니다.
이동 윈도 로그 (Sliding Window Log) 알고리즘
동작 원리
이동 윈도 로그 알고리즘은 시간의 흐름에 따라 요청을 유연하게 처리할 수 있는 방법입니다. 이 알고리즘은 윈도의 고정된 크기를 유지하면서 시간이 지남에 따라 윈도를 '슬라이딩' 시키는 방식으로 작동합니다.
- 로그 기록: 각 요청이 들어올 때, 그 요청의 타임스탬프를 로그에 기록합니다. 타임스탬프 데이터는 보통 Redis의 정렬 집합(sorted set)같은 캐시에 보관합니다.
- 이동 윈도: 현재 시간을 기준으로 과거 일정 시간(예: 1분) 동안의 요청만을 고려합니다. 시간이 지나면서 이 윈도는 계속 앞으로 이동합니다.
- 윈도 업데이트: 새로운 요청이 들어올 때마다 윈도를 업데이트하여, 오래된 요청을 윈도에서 제거하고 최근 요청을 포함시킵니다.
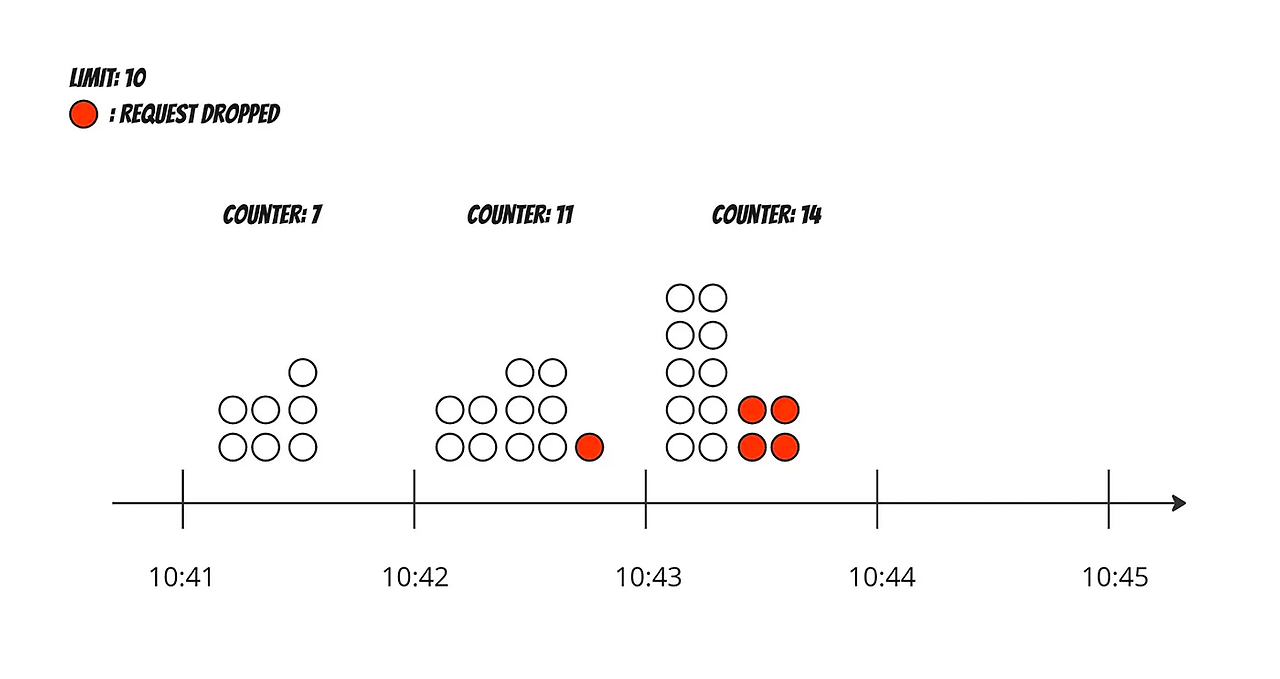
장점
- 유연성: 이동 윈도 로그는 시간이 지남에 따라 요청을 더 유연하게 처리할 수 있어, 순간적인 트래픽 증가에도 잘 대응할 수 있습니다.
- 정밀한 제어: 어느 순간의 윈도를 보더라도 허용되는 요청의 개수는 시스템의 처리율 한도를 넘지 않습니다.
단점
- 자원 소모: 각 요청의 타임스탬프를 저장하고 관리해야 하므로, 많은 요청을 처리하는 시스템에서는 메모리 사용량이 증가할 수 있습니다.
- 구현 복잡성: 이동 윈도 로그 알고리즘은 다른 방법에 비해 구현이 복잡할 수 있으며, 정확한 시간 관리와 로그 처리가 필요합니다.
이동 윈도 카운터 (Sliding Window Counter) 알고리즘
동작 원리
이동 윈도 카운터 알고리즘은 처리율을 제한하고, 시스템의 부하를 관리하는 데 사용되는 방법입니다. 이 알고리즘은 특히 동적인 웹 애플리케이션과 서비스에서 유용하게 사용됩니다.
- 시간 윈도: 시간을 작은 단위로 나누어 각 단위마다 요청 수를 세는 카운터를 둡니다.
- 이동: 윈도는 시간이 지남에 따라 '이동'합니다. 즉, 새로운 시간 단위가 시작될 때마다 최신 요청을 반영하여 카운터를 업데이트합니다.
- 요청 제한: 설정된 시간 동안 허용된 최대 요청 수를 넘으면, 추가 요청은 거부되거나 지연됩니다.
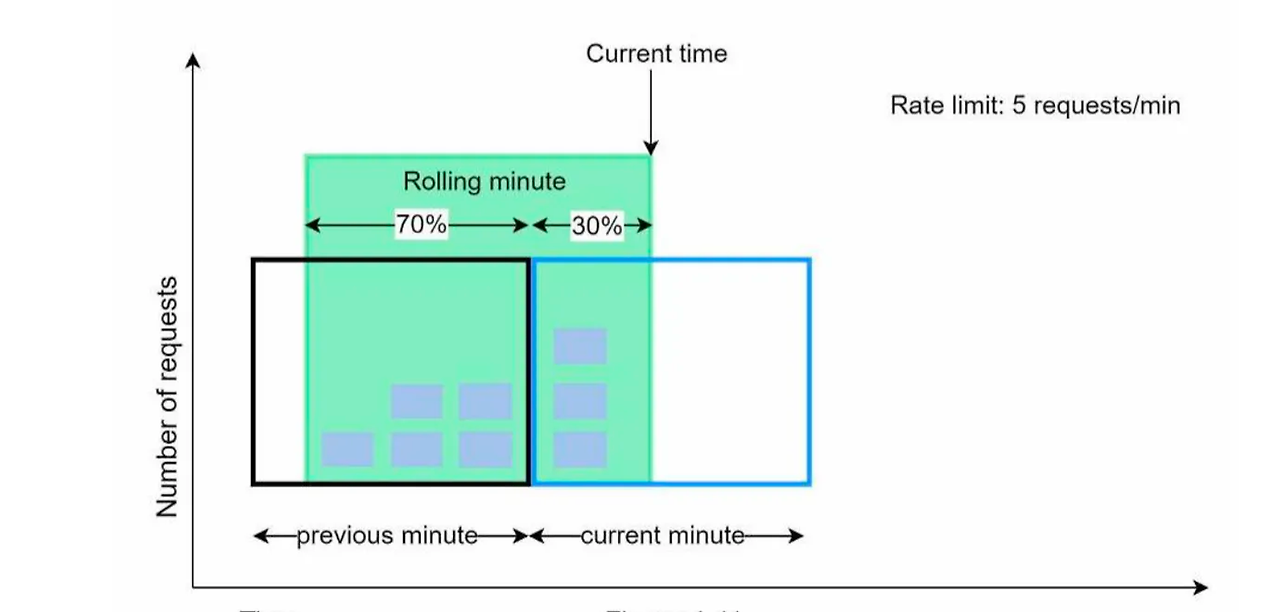
장점
- 이전 시간대의 평균 처리율에 따라 현재 윈도의 상태를 계산하므로 짧은 시간에 몰리는 트래픽에 잘 대응합니다.
- 정밀한 제어: 시간 단위로 요청을 세밀하게 관리할 수 있어, 순간적인 트래픽 증가에도 유연하게 대응할 수 있습니다.
- 효율적인 자원 사용: 고정 윈도 카운터에 비해 더 많은 요청을 처리할 수 있으며, 자원을 보다 효율적으로 사용합니다.
단점
- 구현 복잡성: 이동 윈도 카운터는 구현이 복잡할 수 있으며, 시간 관리와 카운터 업데이트에 주의가 필요합니다.
- 메모리 사용량: 각 시간 단위마다 카운터를 유지해야 하므로, 많은 요청을 처리하는 시스템에서는 메모리 사용량이 증가할 수 있습니다.
구현
처리율 제한 로직의 신규 정책은 토큰 버킷알고리즘을 조금 변경하여 구현해야 했다. 정책은 다음과 같았다.
- rate(초)동안 count(요청횟수)회 허용한다고 가정한다.
- 최초 요청이 들어왔을 때 rate(초) 타이머가 동작한다.
- rate(초)범위 안에서는 count(요청횟수)회 연속으로 요청을 할 수 있다.
- 최초 요청으로부터 rate(초) 뒤 요청 할 수 있는 토큰이 한번에 생성된다. (count 개수만큼)
- rate(초)안에 토큰을 전부 사용하지 못하더라도 토큰이 생성 될 때는 최대치인 count개를 넘지 않는다.
- 토큰을 전부 사용 했을 때 요청 거부와 다음 토큰이 생성되기까지 남은 시간을 반환한다.
- rate(초)에 적용 할 수 있는 최소 주기는 0.00005초 이다.
위 알고리즘 방식은 특정 구간(토큰이 생성되는 시간 앞뒤)에서 최대 2n - 1개의 요청이 몰릴 수 있으니 참고하자.
처리율 제한 장치(rate limiter) 개선
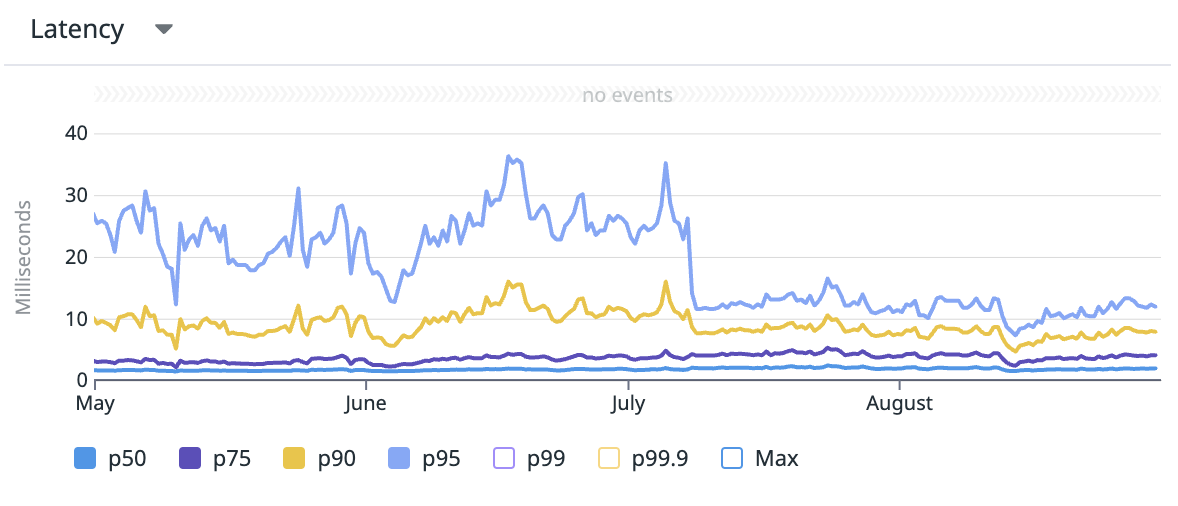
rate limiter 개선 후 datadog에서 latency 그래프를 보았을 때 개선정도를 육안으로 확인 할 수 있었다.
lua 스크립트 코드
local keys = redis.call('mget', KEYS[1], KEYS[2]) -- 두 키의 값을 한번에 가져옴
local tokens = tonumber(keys[1]) or tonumber(ARGV[1]) -- 현재 버킷의 토큰 개수
local last_fill = tonumber(keys[2]) or tonumber(ARGV[3]) -- 마지막으로 토큰이 충전된 시간
local capacity = tonumber(ARGV[1]) -- 버킷의 최대 토큰 수
local refill_interval = tonumber(ARGV[2]) -- 토큰이 다시 채워지는 시간 간격 (초)
local now = tonumber(ARGV[3]) -- 현재 시간
local ttl = refill_interval * 2 * 1000 -- 넉넉하게 ttl값 설정 (초)
-- 경과 시간 계산
local elapsed = now - last_fill
-- 충전 시간이 경과 했거나 첫 요청(elapsed == 0)인 경우 토큰을 최대로 채움
if elapsed >= refill_interval or elapsed == 0 then
tokens = capacity
redis.call('psetex', KEYS[1], ttl, tokens)
redis.call('psetex', KEYS[2], ttl, now)
end
if tokens > 0 then
-- 토큰이 있는 경우, 토큰 하나 소모
tokens = tokens - 1
redis.call('psetex', KEYS[1], ttl, tokens)
return {1, tokens, 0} -- 요청 허용, 남은 토큰 수, 대기 시간 0초 반환
else
-- 토큰이 없으면 다음 충전 시간까지 기다려야 함
local time_to_next_refill = refill_interval - elapsed
return {0, tokens, time_to_next_refill} -- 요청 거부, 남은 토큰 수, 대기 시간 반환
end
ratelimit.ts 코드
import assert from 'assert';
type Rate = [number, number];
type RateLimitResponse = {
available: boolean;
retryAfter: number;
}
const TOKEN_BUCKET_BUST_FILL_ALGO = 'lua script...';
export class RateLimitV2 {
static bustFillLuaScript: string = TOKEN_BUCKET_BUST_FILL_ALGO;
static bustFillLuaScriptHash: string = crypto
.createHash('sha1')
.update(TOKEN_BUCKET_BUST_FILL_ALGO, 'utf8')
.digest('hex');
// ...중략
constructor() {
// ...중략
}
static async ratelimit(client: RedisClientType, keyPfx: string, rate: Rate): Promise<RateLimitResponse> {
if (rate[1] === 0) {
return {
available: true,
retryAfter: 0,
};
}
assert(0.0005 <= rate[1], 'ratelimit time is too small');
// KEYS
const baseKey = `${keyPfx}.ratelimit`;
const keys = [`${baseKey}.tokens`, `${baseKey}.timestamp`];
// ARGS (인자값 순서 주의)
const capacity = rate[0].toString();
const refillInterval = rate[1].toString();
const now = (Date.now() / 1000).toString();
const args = [capacity, refillInterval, now];
const scriptLoaded = await client.scriptExists(RateLimitV2.bustFillLuaScriptHash);
if (!scriptLoaded[0]) {
await client.scriptLoad(RateLimitV2.bustFillLuaScript);
}
const result: any = await client.evalSha(RateLimitV2.bustFillLuaScriptHash, {keys, arguments: args});
assert(result.length === 3);
assert(result[0] == 0 || result[0] === 1);
assert(typeof result[1] === 'number' && typeof result[2] === 'number');
return {
available: result[0] === 1,
retryAfter: result[2] * 1000,
};
}
}