데이터베이스와의 전쟁: 암호화폐 거래소 성능 개선기 1편
암호화폐 거래소 DB 성능 개선기 (1편) - 문제점 분석 및 해결 방법 모색
들어가며
암호화폐 거래소의 매칭 엔진은 초당 수백~수천 건의 주문을 처리하며, 각 거래마다 복잡한 정산 로직을 실행합니다. 시간이 지나면서 누적된 데이터가 수십 TB에 달하게 되었고, 이는 심각한 성능 저하로 이어졌습니다. 이 글에서는 실제 프로덕션 환경에서 겪은 성능 문제를 분석하고, 해결 방법을 모색한 과정을 공유합니다.
문제 상황
성능 저하 현상
운영 중인 거래소에서 다음과 같은 문제들이 발생했습니다:
- 신규 주문 접수, 체결, 정산 처리 시간이 점점 증가 (최대 30초 이상)
- Dead lock 발생 빈도 증가
- 주문/체결 상태가 유저에게 전달되기까지 딜레이 발생
데이터 규모 분석
문제의 근본 원인을 파악하기 위해 데이터베이스 테이블 크기를 조사했습니다:
| 테이블 | 테이블 크기 | 인덱스 크기 | 총 합계 | 용도 |
|---|---|---|---|---|
| booktxn | 10 TB | 721 GB | 11 TB | 장부 거래 내역 |
| tradeorderstate | 3.9 TB | 3.2 TB | 7.1 TB | 주문 상태 |
| tradetxn | 5.3 TB | 1.1 TB | 6.4 TB | 체결 내역 |
| tradeorderreception | 3.6 TB | 2.8 TB | 6.4 TB | 주문 접수 |
| customerbalancehistory | 2.2 TB | 1.7 TB | 3.9 TB | 잔고 변경 이력 |
| tradeordercancelsettlement | 0.9 TB | 0.8 TB | 1.7 TB | 주문 취소 정산 |
| tradetradesettlement | 0.1 TB | 0.09 TB | 0.2 TB | 체결 정산 |
총 스토리지: 약 37TB
병목 지점 분석
체결 정산 로직 (settleTrade)
가장 큰 병목이 발생하는 체결 정산 로직을 분석했습니다:
func (settler *OrderSettler) settleTrade(...) error {
// 1. 트랜잭션 시작 및 중복 정산 체크
// - 정산 이력 테이블을 조회하여 이미 처리된 거래인지 확인
SELECT ... FROM tradetradesettlement WHERE ...
// 2. 주문 Row Lock 획득
// - 대용량 주문 테이블(3.6TB)에서 해당 주문을 FOR UPDATE로 잠금
SELECT ... FROM tradeorderreception WHERE ... FOR UPDATE
// 3. 고객 잔고 조회 및 Lock 획득
// - 거래에 참여하는 모든 계정의 잔고를 조회하고 동시 수정 방지를 위한 잠금 설정
SELECT ... FROM get_customer_balances_for_update(...)
// 4. 체결 금액 및 수수료 계산
// - 매수/매도 금액 계산
// - 거래 수수료 및 수수료 할인 적용
// - 시스템 계정으로의 수수료 이체 금액 계산
st.Step1() // 거래 금액 분할 계산
st.Step2() // 수수료 정산 계산
// 5. 장부 거래 기록 생성
// - 대용량 장부 테이블(10TB)에 새로운 거래 기록 삽입
// - 복수의 인덱스 업데이트 발생
INSERT INTO booktxn(...) VALUES (...) RETURNING ...
// 6. 고객 잔고 업데이트
// - 내부 프로시저를 통해 관련된 모든 계정의 잔고를 원자적으로 업데이트
SELECT ... FROM internal_update_balances(...)
// 7. 정산 완료 기록
// - 정산 처리가 완료되었음을 기록 (중복 방지용)
INSERT INTO tradetradesettlement (...) VALUES (...)
// 8. 주문 상태 업데이트
// - 대용량 주문 테이블(3.6TB)에서 체결된 금액만큼 업데이트
UPDATE tradeorderreception SET ... WHERE ...
}
병목 지점별 분석
| 단계 | 대상 테이블 | 크기 | 특징 | 영향도 |
|---|---|---|---|---|
| 주문 잠금 | tradeorderreception | 3.6 TB | PK 조회 + FOR UPDATE | 높음 |
| 장부 거래 삽입 | booktxn | 10 TB | 대용량 테이블 쓰기 + 인덱스 업데이트 | 매우 높음 |
| 잔고 업데이트 | customerbalance, booktxn | 0.7GB, 2.2TB | 대용량 테이블 조회 + row 수정 | 높음 |
| 정산 기록 삽입 | tradetradesettlement | 0.1 TB | 인덱스 업데이트 | 중간 |
| 주문 상태 갱신 | tradeorderreception | 3.6 TB | 대량 인덱스 → 랜덤 I/O | 높음 |
핵심 문제점 도출
Datadog과 AWS 모니터링 결과, get_customer_balances_for_update 프로시저에서 deadlock이 자주 발생했지만, 이 프로시저는 customerbalance 테이블(0.7GB)만 다룹니다.
실제 병목은 수 TB 규모의 테이블에서 발생하는 I/O 작업이었습니다:
- 대용량 테이블에 대한 INSERT/UPDATE 연산
- 인덱스 크기 증가로 인한 랜덤 I/O 증가
- VACUUM 작업 부하 증가
해결 방법 모색
1. 데이터 클렌징 전략
오래된 데이터를 안전하게 제거하기 위한 전략을 수립했습니다:
클렌징 대상 테이블 및 기준
booktxn (장부 거래)
- 실시간 스트리밍 서비스에서 시퀀스 기반으로 읽어가는 데이터
- 다른 시스템들이 현재 읽고 있는 최소 시퀀스를 조회하여, 모든 시스템이 이미 처리한 데이터만 안전하게 제거
- 안전 마진을 두어 혹시 모를 시스템 지연을 고려
tradetxn (체결 내역)
- 마켓별로 독립적인 스트림으로 관리되는 체결 데이터
- 각 마켓마다 여러 컨슈머 서비스가 존재하며, 모든 컨슈머가 처리 완료한 데이터만 제거
- 환율 계산, 알림 서버, 시장 데이터 집계 등 다양한 서비스에서 사용 중
tradeorderstate (주문 상태)
- 주문의 생명주기(접수→진행중→완료/취소)를 추적하는 테이블
- 완료된 주문 데이터는 제거 가능하나, 다음 주문 번호 생성을 위해 마지막 시퀀스는 반드시 보존 필요
customerbalancehistory (잔고 변경 이력)
- 사용자 잔고의 모든 변경 이력을 기록한 감사 로그성 데이터
- 실시간 서비스에서는 참조하지 않으며, 주로 CS 문의나 회계 감사 시 조회
- 테이블 전체를 S3에 Parquet 파일로 아카이빙 후 삭제해도 시스템에 영향 없음
- 필요 시 Athena를 통해 아카이빙된 데이터 조회 가능
booktxnapilog (API 로그)
- 외부 API 호출 이력을 기록한 디버깅용 로그 데이터
- 실시간 서비스와 무관하며, 일정 기간이 지나면 조회 빈도가 극히 낮음
- S3 아카이빙 후 전체 삭제 가능
클렌징 불가 테이블
- customerbalance: 현재 잔고 (삭제 불가)
- tradetradesettlement: 정산 기록 (삭제 불가)
- tradeorderreception: 활성 주문 데이터 포함 (명확한 기준 부재)
2. Aurora I/O-Optimized 도입
데이터 클렌징 방안을 검토하면서, 안정적인 데이터 아카이빙 사례들을 찾아보았습니다. AWS 공식 문서에서 RDS에서 S3로 데이터를 내보내는 방법, Athena를 활용한 아카이빙 데이터 쿼리 등을 학습하던 중, Aurora I/O-Optimized라는 새로운 스토리지 구성 옵션을 발견했습니다.
AWS Aurora는 두 가지 스토리지 구성을 제공합니다:
- Aurora Standard: 스토리지 + I/O 요청당 과금
- Aurora I/O-Optimized: 스토리지만 과금 (I/O 무료, 단 스토리지 단가 상승)
I/O-Optimized 선택 기준
AWS 공식 문서에 따르면:
I/O 지출이 Aurora 청구서의 25%를 초과하는 경우, Aurora I/O-Optimized를 통해 I/O 집약적 워크로드의 비용을 최대 40% 절감할 수 있습니다.
실제 IOPS 사용량 (CloudWatch 지표)
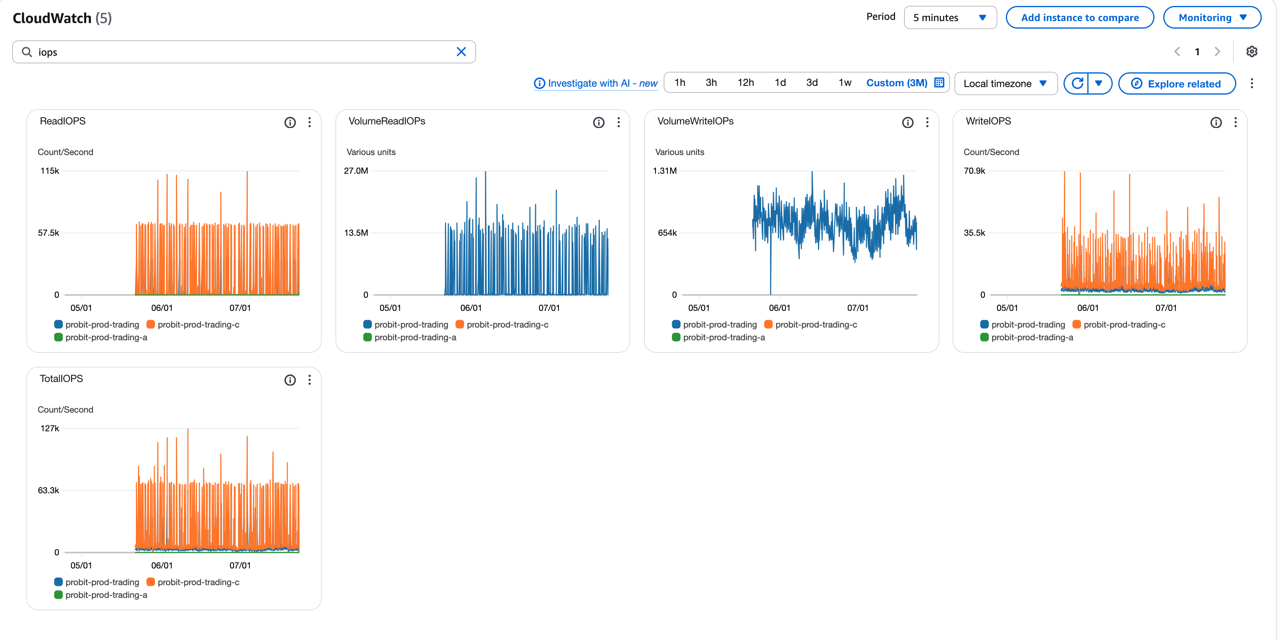
위 그래프에서 확인할 수 있듯이, trading DB는 높은 IOPS를 지속적으로 사용하고 있습니다:
- ReadIOPS: 평균 57.6k/초
- WriteIOPS: 평균 35.5k/초
- VolumeReadIOPS: 평균 13.5M
- VolumeWriteIOPS: 평균 654k
이러한 높은 I/O 패턴은 I/O-Optimized 적용 시 큰 비용 절감 효과를 기대할 수 있음을 의미합니다.
Aurora 요금 비교
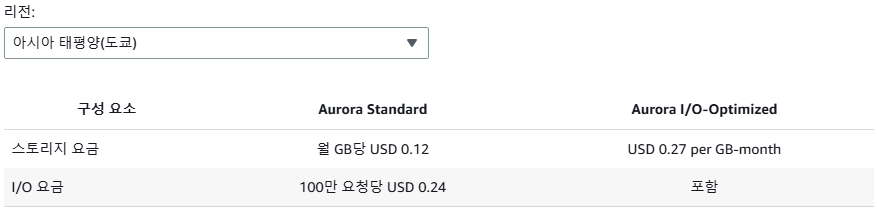
| 구성 요소 | Aurora Standard | Aurora I/O-Optimized |
|---|---|---|
| 스토리지 요금 | 월 GB당 $0.12 | 월 GB당 $0.27 |
| I/O 요금 | 100만 요청당 $0.24 | 포함 |
우리의 경우 I/O 비용이 월 $6,465 (전체의 59%)를 차지하고 있어, 스토리지 단가가 2배 이상 높아지더라도 I/O-Optimized가 유리합니다.
비용 분석
AS-IS (현재 비용)
| 구분 | trading DB | trading_web DB | 합계 |
|---|---|---|---|
| 스토리지 | 37TB → $4,446 | 18TB → $2,190 | $6,636 |
| I/O | $6,465 (59%) | $3,456 (61%) | $9,921 |
| 인스턴스 | $4,000 | $4,000 | $8,000 |
| 월 합계 | $14,911 | $9,646 | $24,557 |
TO-BE (데이터 클렌징 + I/O-Optimized 적용)
| 구분 | trading DB | trading_web DB | 합계 | 절감액 |
|---|---|---|---|---|
| 스토리지 | 13TB → $3,600 | 18TB → $2,190 | $5,790 | $846 |
| I/O | $0 | $3,456 | $3,456 | $6,465 |
| 인스턴스 | $5,200 | $4,000 | $9,200 | -$1,200 |
| 월 합계 | $8,800 | $9,646 | $18,446 | $6,111 (25%) |
TO-BE v2 (양쪽 DB 모두 클렌징 시)
| 구분 | trading DB | trading_web DB | 합계 | 절감액 |
|---|---|---|---|---|
| 스토리지 | 13TB → $3,600 | 6TB → $2,211 | $5,811 | $825 |
| I/O | $0 | $0 | $0 | $9,921 |
| 인스턴스 | $5,200 | $5,200 | $10,400 | -$2,400 |
| 월 합계 | $8,800 | $7,411 | $16,211 | $8,346 (34%) |
참고: I/O-Optimized는 인스턴스 비용이 약 30% 증가하지만, I/O 비용이 완전히 제거되어 전체적으로 큰 비용 절감 효과를 얻을 수 있습니다. 특히 우리 서비스는 I/O 비용이 전체의 40%를 차지하고 있어 I/O-Optimized 적용의 효과가 매우 큽니다.
3. 점검 시나리오 수립
데이터 클렌징 작업을 안전하게 수행하기 위해 여러 시나리오를 검토했습니다.
1안: 신규 클러스터 전환 방식
절차:
- 신규 Aurora 클러스터 생성
- PostgreSQL Logical Replication (pub/sub)을 통해 기존 클러스터에서 신규 클러스터로 실시간 데이터 동기화
- 신규 클러스터에서 데이터 클렌징 사전 작업 수행
- 점검 시작 → 모든 Pod 중지
- 기존 클러스터 스냅샷 생성 (롤백용)
- 신규 클러스터에서 최종 데이터 클렌징 완료
- EKS 환경 변수 변경 (RDS 엔드포인트를 신규 클러스터로 전환)
- Pod 재시작
- 거래 봇 테스트
- 서비스 재개
장점:
- 사전에 대부분의 작업을 완료하여 점검 시간 단축 가능
- 기존 클러스터를 그대로 유지하여 롤백 용이
단점:
- 신규 클러스터 비용 발생 (점검 기간 동안)
- PostgreSQL Logical Replication 설정 및 관리 필요
- EKS 환경 변수 변경으로 인한 리스크
- 롤백 시 다시 환경 변수를 되돌려야 함
2안: 테이블 Rename 방식
절차:
- 점검 시작 → 모든 Pod 중지
- 기존 테이블을
_old로 renameALTER TABLE booktxn RENAME TO booktxn_old; ALTER TABLE tradetxn RENAME TO tradetxn_old; -- 인덱스도 함께 rename - 동일한 이름으로 신규 테이블 생성
- 필요한 데이터만
_old테이블에서 신규 테이블로 마이그레이션INSERT INTO booktxn SELECT * FROM booktxn_old WHERE ...; - Pod 재시작
- 거래 봇 테스트
- 서비스 재개
- 문제 없으면 나중에
_old테이블 S3 아카이빙 후 삭제
장점:
- 추가 클러스터 불필요
- EKS 환경 변수 수정 불필요
- 스냅샷 생성 불필요 (테이블 rename만으로 즉시 롤백 가능)
- 롤백 시간 최소화 (테이블 rename만 원복하면 됨)
- 사이드 이펙트 최소화
단점:
- 점검 시간 내에 모든 작업을 완료해야 함
- 데이터 마이그레이션 시간이 길어질 수 있음
최종 선택: 결과적으로 **2안(테이블 Rename 방식)**을 채택했습니다. 롤백이 가장 빠르고 안전하며, 추가 비용이 발생하지 않는다는 점이 결정적이었습니다. 2편에서 실제 점검 과정을 확인해주세요!
4. 롤백 계획
각 시나리오별 롤백 방안도 상세히 수립했습니다.
케이스 1: DB 버전 업그레이드 실패
상황: PostgreSQL 15.4 → 15.10 업그레이드 중 호환성 문제 발생
롤백 방안:
- 업그레이드 전에 생성한 15.4 버전 스냅샷으로 복원
- 예상 소요 시간: 약 1시간 30분 (37TB 기준)
- 점검 시간 연장 필요
케이스 2: 1안(신규 클러스터 전환) 실패 시
상황: 신규 클러스터 전환 후 거래 기능 불능 또는 데이터 정합성 오류 발견
롤백 방안:
- EKS 환경 변수를 기존 클러스터 엔드포인트로 원복
- 전체 Pod 재시작
- 기존 클러스터로 서비스 복구
소요 시간: 약 15분 데이터 손실 리스크: Pod 중지 시점 이후 발생한 데이터는 신규 클러스터에만 존재하므로, 롤백 시 해당 데이터 손실 가능 (점검 중에는 거래 불가하므로 실제 손실 리스크는 낮음)
케이스 3: 2안(테이블 Rename) 실패 시
상황: 데이터 마이그레이션 후 거래 기능 오류 또는 데이터 정합성 문제 발견
롤백 방안:
- 신규 테이블을
_new로 rename (나중에 분석용)ALTER TABLE booktxn RENAME TO booktxn_new; ALTER TABLE tradetxn RENAME TO tradetxn_new; _old테이블을 원래 이름으로 renameALTER TABLE booktxn_old RENAME TO booktxn; ALTER TABLE tradetxn_old RENAME TO tradetxn;- 인덱스도 동일하게 원복
- 전체 Pod 재시작
- 서비스 복구
소요 시간: 약 5분 (테이블 rename은 메타데이터만 변경하므로 매우 빠름)
데이터 손실: 없음 (원본 데이터를 _old 테이블에 그대로 보존)
다음 편 예고
2편에서는 실제 점검 과정에서 발생한 이슈들과 해결 과정, 그리고 성능 개선 결과를 상세히 다룹니다.
- 6시간의 점검 과정
- 성능 개선 결과 측정
- 운영 비용 절감 효과
참고 자료